打开
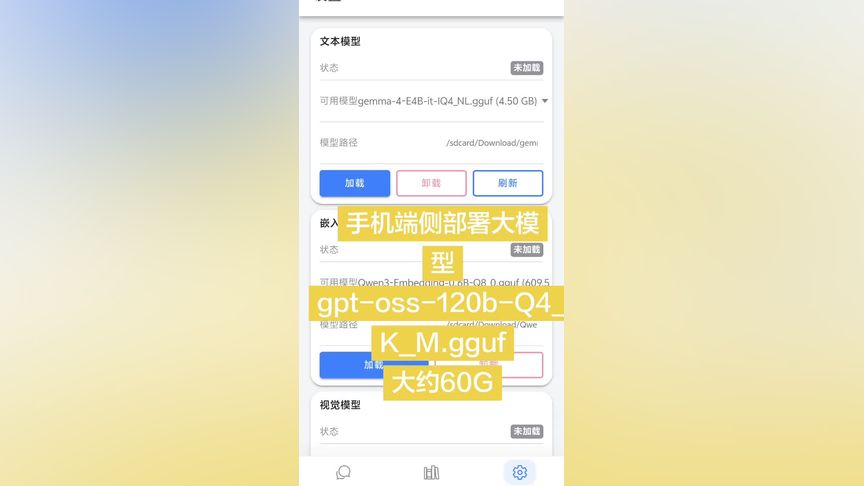


端侧手机本地部署大模型 手机型号:VivoX100 技术栈: 使用 Vue3 + Ionic + Capacitor 作
#大模型 #大模型部署 #端侧大模型 端侧手机本地部署大模型 手机型号:VivoX100 技术栈: 使用 Vue3 + Ionic + Capacitor 作为前端, Android原生 + Kotlin + JNI 作为后端,推理引擎为 llama.cpp。 测试模型: gpt-oss-120b-Q4_K_M.gguf 大约60G,总参数:116.8B(约 117B) 激活参数(每 token):5.13B 初步测试基本达到预期,只是纯CPU推理吞吐压力大,不过,我已经在做了GPU介入,或许能够提高推理速度。